반응형
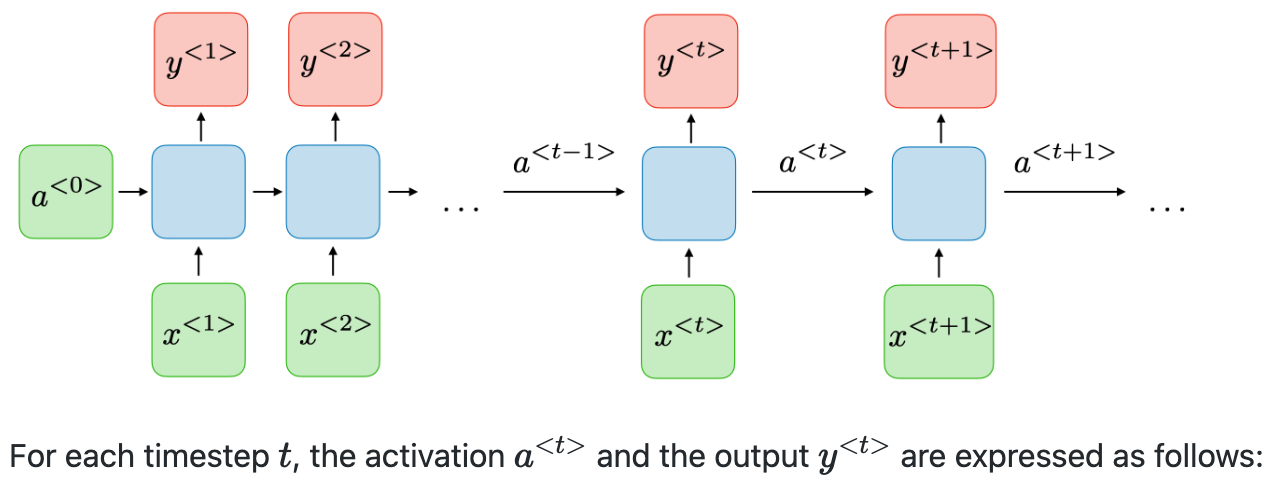
RNN?
이전의 hidden state를 가지면서 이전 출력을 입력으로 사용가능하도록 하는 신경망(이전 시점을 고려)
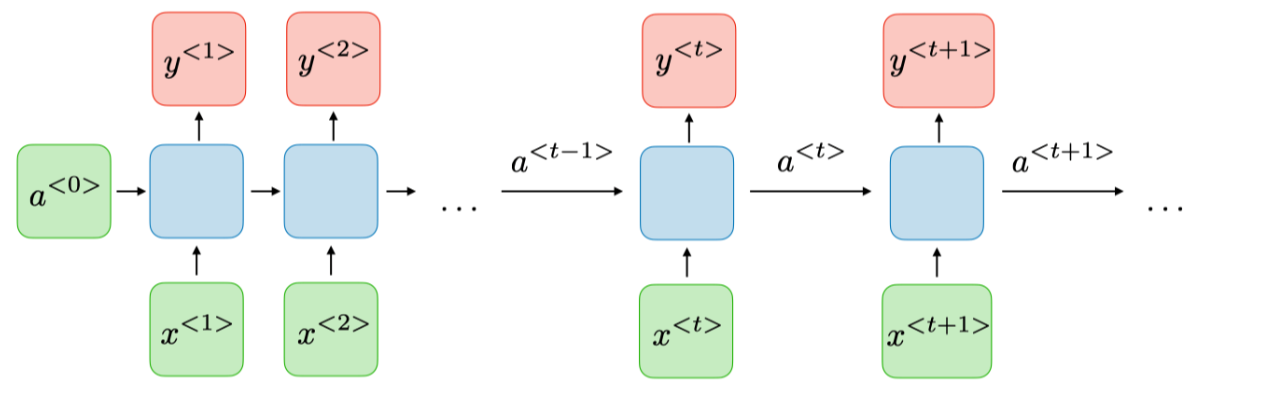
관련 수식
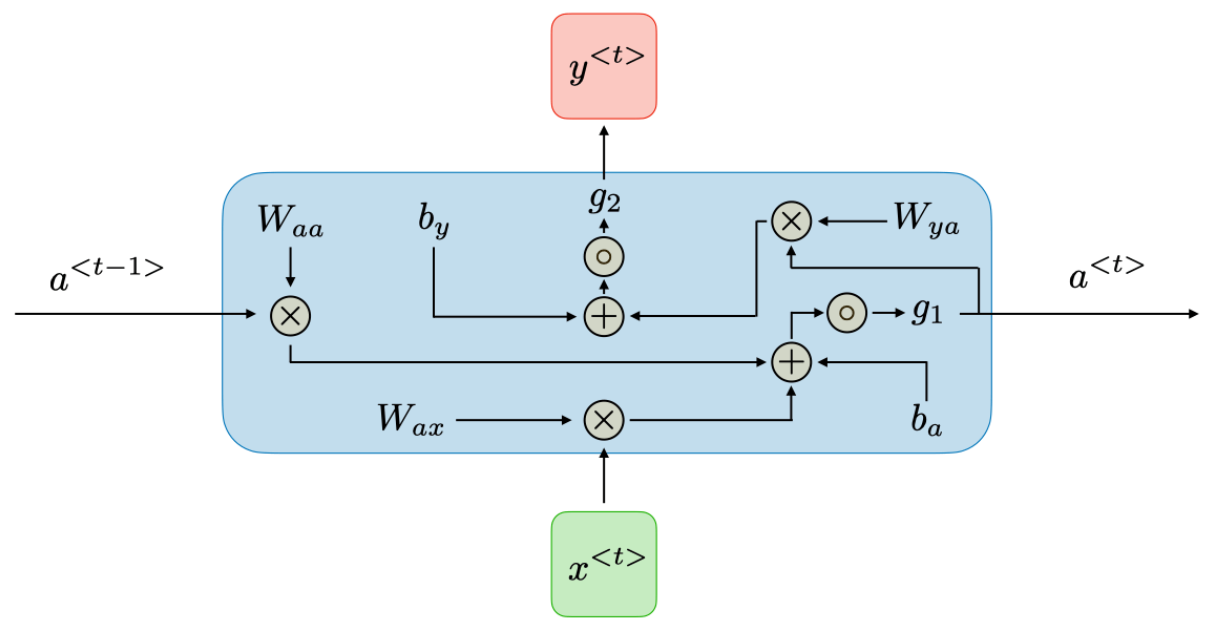
1. hidden state : $$ a^{<t>} = g_1\left(W_{aa}a ^{t-1} + W_{ax}x^{t}+b_a \right) $$
2. output state : $$ y^{<t>} = g_{2}\left ( W_{ya}a^{<t>} + b_y \right )$$
RNN의 내부
| 장점(Advantages) | 단점(Cons) |
|
|
Loss function
$$ \mathcal{L}\left ( \hat{y}, y \right ) = \sum_{t=1}^{T_y} \mathcal{L}\left ( \hat{y}^{<t>} ,y^{<t>} \right ) $$
Backpropagtion throught time(BPTT)

Reference :
[1] Afshine Amidi, Shervine Amidi, "CS 230 - Deep Learning", https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-recurrent-neural-networks
반응형
'인공지능 > 기초' 카테고리의 다른 글
| LSTM & GRU (0) | 2024.05.07 |
|---|---|
| (Scaled) Dot-Product Attention (0) | 2024.04.28 |
| Sequence-to-sequence(seq2seq) & Teacher-forcing (0) | 2024.04.27 |
| Applications of RNNs (0) | 2024.03.23 |